DATA MINING - CLASSIFICATION ALGORITHM - EVALUATION
Narendran Calluru Rajasekar
May 8th, 2009
Supervised by
Dr. Sin Wee Lee

MSC Internet Systems Engineering
University of East London,
Table of Contents
2 Implementation of Classification Algorithm (Part 1)
2.1 Dataset - Network Intrusion Detection
2.1.1 Introduction of the Dataset
2.1.5 Input Encoding / Input Representation
2.2 Implementation of Algorithms
2.2.1 Reasons Why the Particular Tool is Chosen
2.2.2 Implementation Procedure Used in Weka
2.2.3 Implementation Procedure Used in SQL Analysis Services
2.2.4 Detailed analysis of the results with the appropriate screen dumps
2.3 Challenges of Implemented Algorithm
2.3.1 Conclusions and comments
2.3.2 Problems encountered and the solutions
3.2.3 Comparison of Decision Tree (J48) and Neural Networks (Multilayer Perceptron)
3.2.4 Experimental Results of J48 and Multilayer Perceptron
1 Abstract
This paper consists of two parts; the first part consists of implementation of Decision Tree, Naïve Bayes and Neural Networks in Weka and SQL Analysis Services. The attributes such as accuracy and performance are compared among the data before preprocessing and after preprocessing by implementing the above mentioned algorithms. Also screen dumps of tree visualization and implantation steps, tables and charts on the results are provided.
The second part consists of research paper which compare, contrast and evaluates J48 implementation of Decision Trees and Multilayer Perceptron implementation of Neural Networks. It also includes the research topics floating around Decision Trees and Neural Networks.
The above two sections are followed by Appendix (Acronyms) and Bibliography.
Keywords: Data Mining, Decision Trees, Neural Networks, Comparitive Study
2 Implementation of Classification Algorithm (Part 1)
In this section we will discuss implementation of Decision Tree, Neural Network and Naïve Bayes algorithms to the selected dataset and discuss the results of the implemented algorithms.
2.1 Dataset - Network Intrusion Detection
2.1.1 Introduction of the Dataset
The dataset Network Intrusion Detection was chosen from The UCI KDD Archive [1]. The dataset is the collection of network related information that was captured over a period of time. The dataset downloaded from The UCI KDD Archive consists of 41 attributes, 300,000 instances and 38 different classes which are represented in "csv" format.
2.1.2 Dataset Cleaning
Since the dataset downloaded is corrected already, it doesn't contain any missing value or inconsistent values. Hence data cleaning is not required for the selected dataset.
2.1.3 Dataset Transformation
The "csv" format dataset is imported in to SQL table using the Data Transformation Service (DTS) so that it can be used with SQL Analysis Services and it is also converted to ARFF file format to use it with Weka using the import tool available in Weka software.
2.1.4 Dataset Reduction
To meet the objective of coursework, the training dataset was simplified to 5 attributes, 943 instances and 5 different classes. For simplicity and to understand the domain easily the 5 most common attacks (classes) which involves different combinations of Protocol Type and Service were chosen (Table 2.1) from the dataset. These classes are chosen such that it which may help to understand the implementation of algorithm in real time.
| Class | Description |
|---|---|
| back | Denial of service attack which targets apache web server by sending requests consists of many back slashes in the url. |
| guess_passwd | Attack by guessing user password. |
| Ipsweep | Attack in which valid IP addresses in a network is found out which can be used for other attacks. |
| multihop | Attack in which access to a machine is gained and is used for attacking other machines. |
| smurf | Denial of service attack in which the ping request is sent to multiple machines with a spoofed host IP address.Hence the target machine would be flooded with ping replies without the ability to distinguish between real traffic and the spoofed ones. |
Table 2.1 - Description of classes in the dataset.
Using AttributeSelection filter, 8 attributes were selected out of 41 attributes. Using the domain knowledge another 3 attributes were eliminated which is not related to the selected classes. Finally the 5 attributes (Table 2.2) were selected for the case study.
The 300,000 instances was reduced to 943 by randomly selecting 20,000 instances using SQL Analysis Services and then by filtering down to 5 classes.
| Attributes | Description | Type |
|---|---|---|
| Protocol Type | Protocol used (tcp, udp, icmp) | discrete |
| Service | network service on the destination(http, telnet) | discrete |
| Src Bytes | Data bytes transferred from source to destination | continuous |
| Dst Bytes | Data bytes transferred from destination to source | continuous |
| Count | number of connections to the same host as the current connection in the past two seconds | continuous |
Table 2.2 - Description of attributes in the dataset.
2.1.5 Input Encoding / Input Representation
The selected attributes consists of both discrete and continuous attribute types. The attributes Protocol Type and Service are of type discrete and the attribute Src Bytes, Dst Bytes, Count are of continuous type. Since the algorithm to be implemented, process the dataset in number of iterations, the continuous type attribute will increase the load on the algorithm and thereby decreasing the performance. Hence they are converted to discrete values by applying Supervised Discretized method available in Weka. This method also helps to remove the outliers to an extent.
2.1.6 Input format
* ARFF - Attribute-Relation File Format is used as input for Weka.

Figure 2.1 - Sample dataset used in this case study.
* SQL table is used for SQL Analysis Server
2.2 Implementation of Algorithms
2.2.1 Reasons Why the Particular Tool is Chosen
The tools chosen for implementation of algorithms were Weka and SQL Analysis services. The objective of selecting these tools is to understand the basic concepts and also application of these algorithms in real time.
Weka is helpful in learning the basic concepts of data mining where we can apply different options and analyze the output that is being produced.
SQL Analysis Services is a professional tool which is used in the market currently. The Mining Accuracy Chart which includes the Lift Chart and Classification Matrix in SQL Analysis services helps to choose the suitable algorithm for the Dataset. This tool will help us understanding the implementation of data mining techniques in real world applications.
2.2.2 Implementation Procedure Used in Weka
.The transformed ARFF file is fed in to Weka and the classification algorithms are implemented as defined in the following steps:
* In the Preprocess tab, Discretize filter is applied to discretize the attributes Src Bytes, Dst Bytes and Count in the supplied dataset (Figure 2.2).
Figure 2.2 - Choosing Filter
* In the Classify tab, choose the classification algorithm to be implemented and start the analysis to get results (Figure 2.3).
Figure 2.3 - Choosing Algorithm
* The algorithms implemented in this case study are J48 (Decision Tree), Naïve Bayes and Multilayer Perceptron (Neural Network).
* The parameters of each algorithm are changed and analyzed for improvement in accuracy and performance.
2.2.3 Implementation Procedure Used in SQL Analysis Services
The implementation procedure in SQL Analysis Services is as follows:
* A Data Source View (Figure 2.4) is created using the SQL table in which the data source is loaded.

Figure 2.4 - Data Source View and Mining Structure
* Using the Data Source View, a Mining Structure (Figure 2.4) is created in with the Mining Models (Microsoft Decision Trees, Microsoft Neural Network, and Microsoft Naïve Bayes).

Figure 2.5 - Mining Models
* The content type is manually selected or is left with the tool for suggestion.
* The Mining Structure and all its related Models are processed.
* Mining Model Viewer (Figure 2.6) allows us to visualize the models.

Figure 2.6 - Mining Model Viewer
* The Lift Chart provides the Predict Probability for each model and Classification Matrix provides the predicted values against actual value matrix (Figure 2.7).

Figure 2.7 - Classification Matrix
2.2.4 Detailed analysis of the results with the appropriate screen dumps
In this section, the results of implemented algorithms i.e., J48, Naïve Bayes and Multilayer Perceptron in Weka and Microsoft Decision Trees, Microsoft Neural Networks and Microsoft Naïve Bayes in Microsoft SQL Analysis Services are evaluated.
2.2.4.1 Evaluation of J48 Decision Tree Results Generated in Weka
The J48 (Binary Tree) algorithm is implemented for both raw data and discretized data and also by changing the Binary Split Option. The following results are achieved.
| Data | J48 (Binary Split = false)(%) | J48 (Binary Split = true)(%) |
|---|---|---|
| Raw Data | 98.8335 | 99.1516 |
| Discretized Data | 99.2577 | 99.3637 |
Table 2.3 - Accuracy Rate of J48 in Weka
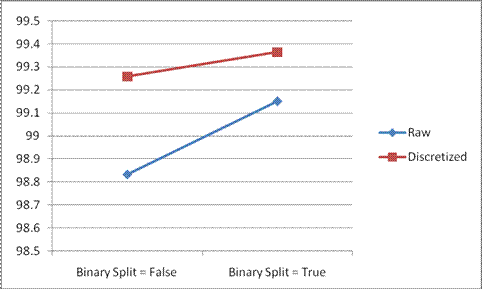
Chart 2.1 - Accuracy Rate of J48 in Weka
The above chart shows that the accuracy rate of the predicted results is always high for discretized data when compared to raw data (un-preprocessed). This is because the Supervised Discretization used for discretization is based on the clustering of data with the knowledge of class. Also the time taken to build model for raw data is high when compared to the time taken to build model for discretized data. When Binary Split option is set to true, the accuracy is further increased. The visualization of all the binary trees is shown below(Figure 2.8, 2.9, 2.10, 2.11).

Figure 2.8 - J48 Decision Tree with Raw Data and Binary Split = False

Figure 2.9 - J48 Decision Tree with Raw Data and Binary Split = True

Figure 2.10 - J48 Decision Tree with Discretized Data and Binary Split = False

Figure 2.11 - J48 Decision Tree with Discretized Data and Binary Split = True
2.2.4.2 Evaluation of Naïve Bayes Results Generated in Weka
The Naïve Bayes algorithm is implemented for both raw data and discretized data and also by changing the Supervised Discretization Option. The following results are achieved.
| Data | Naïve Bayes (Supervised Discretization = false)(%) | Naïve Bayes (Supervised Discretization = true)(%) |
|---|---|---|
| Raw Data | 99.1516 | 99.4698 |
| Discretized Data | 99.5758 | 99.5758 |
Table2.4 - Accuracy Rate of Naïve Bayes in Weka
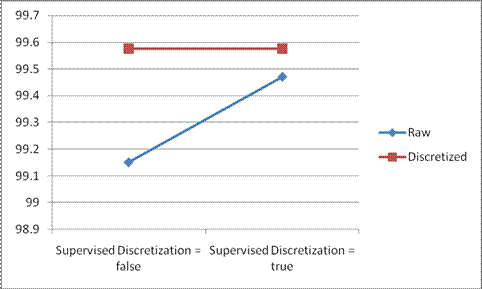
Chart 2.2 - Accuracy Rate of Naïve Bayes in Weka
The above results show that the Naïve Bayes accuracy rate has increase when the attributes are discretized, this is for the same reason that the discretization used in Supervised Discretization which clusters data with the knowledge of class to which it belongs to. It also shows that when the Supervised Discretization option is selected for the raw data, the accuracy rate increases drastically but is not up to the level of the preprocessed data. It is also evident that the accuracy rate increases even when Supervised Discretization is applied for the preprocessed data which is already discretized.
2.2.4.3 Evaluation of Multilayer Perceptron (Neural Networks) Generated in SQL Analysis Services
The Multilayer Perceptron algorithm is implemented for both raw data and discretized data and the following results are achieved. It is evident that the accuracy rate has increased when the algorithm is implemented on preprocessed data.
| Data | Multilayer Perceptron |
|---|---|
| Raw Data | 98.7275 |
| Discretized Data | 99.4698 |
Table 2.5 - Accuracy Rate of Multilayer Perceptron in Weka
2.2.4.4 Evaluation of Results Generated in SQL Analysis Services
The algorithms Microsoft Decision Trees, Microsoft Neural Networks and Microsoft Naïve Bayes are implemented SQL Analysis Services and the following results are achieved. It is evident from the results that the accuracy rate for the Microsoft Neural Networks is high than the Microsoft Decision Trees and Microsoft Naïve Bayes for the analyzed dataset. The preprocessing of data has helped to achieve better accuracy rate for the Microsoft Decision Trees but the accuracy rate for Microsoft Neural Networks has slightly fallen down. Microsoft Naïve Bayes accuracy rate is better than the Microsoft Decision Trees but lower than the Microsoft Neural Networks. The visualization of Microsoft Decision Trees is presented below (Figure 2.12, 2.13).
| Data | Microsoft Decision Trees(%) | Microsoft Neural Networks(%) | Microsoft Naïve Bayes(%) |
|---|---|---|---|
| Raw Data | 98.95 | 99.71 | 99.47 |
| Discretized Data | 99.23 | 99.67 |
Table2.6 - Accuracy Rate of various algorithms implemented in SQL Analysis Services

Chart 2.3 - Accuracy Rate of various algorithms implemented in SQL Analysis Services

Figure 2.12 - Microsoft Decision Tree with Raw Data

Figure 2.13 - Microsoft Decision Tree with Discretized Data
2.3 Challenges of Implemented Algorithm
2.3.1 Conclusions and comments
The table below shows the overall accuracy rate for all the implemented algorithms for the Network Intrusion Detection dataset.
| Data | Decision Tree(%) | Neural Networks(%) | Naïve Bayes(%) | J48 (Binary Split = ture)(%) | Naïve Bayes (Supervised Discretization = true)(%) |
|---|---|---|---|---|---|
| Weka - Raw Data | 98.8335 | 98.7275 | 99.1516 | 0.9674 | 0.9948 |
| Weka - Discretized Data | 99.2577 | 99.4698 | 99.5758 | 0.9826 | 0.9956 |
| SQL Analysis Services - Raw | 98.95 | 99.71 | 99.47 | ||
| SQL Analysis Services - Discretized | 99.23 | 99.67 |
Table 2.7 - Percentage of Correctly Classified Instances
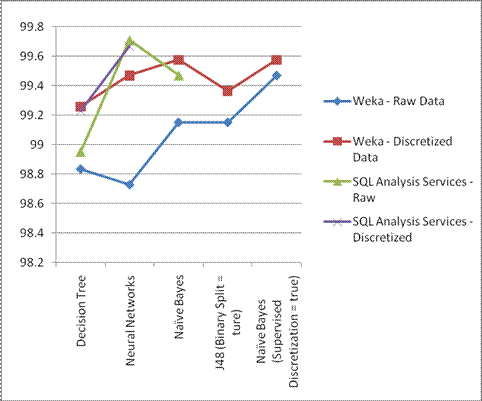
Chart 2.4 - Overall accuracy rates of implemented algorithms
From the above chart it is evident that Microsoft Neural Networks has shown the highest accuracy rate for the Network Intrusion Detection dataset when it is applied for the raw data set, whereas all the other algorithms has shown better accuracy rate after preprocessing (Discretization) of data. In general the above result shows drastic accuracy rate changes among algorithms when raw data is used, where as the accuracy rate is consistent for the implemented algorithms after preprocessing of data. Hence the better accuracy rate depends on the choice of algorithm along with the parameters such as selection of attributes along with domain knowledge, preprocessing of data etc.
2.3.2 Problems encountered and the solutions
* The volume of dataset that was downloaded from Internet was huge, and was not able to open in regular document editors or MS Excel. Used Data Transformation Service (DTS) in SQL Server to import the data into the SQL Server database. Later reduced the data and exported to flat file to use it in Weka.
* Microsoft Naïve Bayes algorithm didn't accept the continuous data type. Converting continuous data type to discrete helped to overcome the problem.
* Weka sometimes crashed when the memory exceeded 256MB limit (default). Increased the memory limit by changing the value in batch file which is used to start Weka.
3 Research (Part 2)
Compare, contrast and evaluate Decision Tree based algorithms for data mining with the approach taken by Neural Networks.
3.1 Introduction
In real world data is being collected everywhere, and everyone is eager in extracting knowledge out of it and use it to improve their performance. Everyone has different motive for example, business people would need to improve their business and make profit out of it. Physicians may aim at discovering knowledge out of medical records to prevent disease. Network administrators would need to keep their network secure hence they would aim at detecting anomalies to prevent intrusion. It is impractical to manually analyze the data and extract knowledge as the volume of data is very high. Hence, we aim at finding patterns to discover knowledge from the raw data which is called data mining.
There are different definitions floating around for data mining and there are various techniques to find the patterns from the raw data. Two of such techniques to extract pattern from the raw data are Decision Trees and Neural Networks. In this paper, we will compare, contrast and evaluate J48 implementation of C4.5 Decision Tree algorithm and Multilayer Perceptron which is Neural Network based algorithm.
(Simona Despa, 2003) defines "Data Mining is the process of data exploration to extract consistent patterns and relations among variables that can be used to make valid predictions".
3.2 Research contents
3.2.1 Decision Trees
The decision tree consists of three elements, root node, interior node and a leaf node. Top most element is the root node. Leaf node is the terminal element of the structure and the nodes in between is called the interior node. The decision tree is constructed based on "Divide and Conquer" [3]. That is the tree is formed by framing rules which will branch out from the nodes and sub-nodes until the decision is made. There are different methods of forming the decision rules for Decision Trees i.e., the nodes are selected from the top level based on quality attributes such as Information Gain, Gain Ratio, Gini Index etc. The C 4.5 Decision tree uses Gain Ratio to construct the tree, the element with highest gain ratio is taken as the root node and the dataset is split based on the root element values. Again the information gain is calculated for all the sub-nodes individually and the process is repeated until the prediction is completed.

Figure 3.1- Example of a Decision Tree
3.2.2 Neural Networks
Multilayer Perceptron (MLP) is a neural network based algorithm which has input layer, hidden layer and output layer [3]. The neurons present in the input layer define the input values. The probabilities of inputs are assigned weights before given to the neurons in the hidden layer. Greater the weight, the neuron favors the result. Finally the neurons in the output layer represent the outcome. Neural networks can be applied to any situation virtually provided that relationship exists between the input and the output. The neurons contain activation function through which the signal is passed to predict the output. There are two types of trainings used in neural networks, supervised and unsupervised training. The supervised training algorithm generally used for MLP is back-propagation algorithm. Back propagation algorithm is where the predicted value is compared with the actual value and if the mean squared error is more, the process is repeated again until the mean squared error is minimized [4].

Figure 3.2 - Example of a Neural Network
3.2.3 Comparison of Decision Tree (J48) and Neural Networks (Multilayer Perceptron)
The elements of the Decision Tree are called nodes and the elements of Neural Networks are called neurons. The Decision Tree is constructed using "Divide and Conquer" based on the gain ratio i.e., the attribute with the highest information gain in considered as root node and the process is repeated, whereas Neural Networks is constructed using Back Propagation which is done recursively until mean squared error is minimal i.e., the mean squared error is calculated for the predicted value and the actual value and is repeated until it is minimal [3]. In Decision Trees prediction is based on the rules framed by splitting of nodes into branches based on information gain [8], whereas in Neural Networks the prediction is based on the activation function built as a result of back-propagation or learning process [8]. However, both of them are based on the Supervised Learning.
Decision Trees can be used for both numerical and nominal inputs and is easy to interpret where as Neural Networks can be used only for numerical data usually normalized within the range 0 to 1 and is difficult to interpret [7] [8].
Multilayer Perceptron might over fit the training unless the measures like cross validation are used wisely and similarly the drawbacks using J48 is that the splits may be unbalanced i.e., one partition much larger than the other [9]. Also the time taken to construct Mulitlayer Perceptron is very high when compared to the time taken to construct J48 Decision Tree. The data required to train Neural Network is high compared to all other algorithms.
3.2.4 Experimental Results of J48 and Multilayer Perceptron
The experimental results performed on Network Intrusion Detection presented in Section 2 shows that In Weka the accuracy of Multilayer Perceptron is less than J48 algorithm when experimented on un-preprocessed data where as Multilayer Perceptron had shown high accuracy than J48 when run on preprocessed (discretized) data. In SQL Analysis Service Neural Network has performed far high than any other algorithm (Chart 2.8).
Also, for the data which consist of 973 instances, 5 classes and 5 attributes, the training time consumed for building Multilayer Perceptron was 0.07 seconds which is very high when compared to J48 which was almost 0 seconds.
The paper "Neural Networks Vs Decision trees on Intrusion Detection" submitted by Yacine Bouzida for KDD Cup '99 concludes that neural network performs better for generalization but didn't perform well on new type of attacks (unknown classes), whereas Decision trees has performed well on both generalization and new type of attacks.
Though Neural Networks produces high degree of accuracy, the interpretation is very difficult. Hence in the IEEE Journal [10], author proposes a new form of algorithm called artificial neural-network decision tree algorithm (ANN-DT). This algorithm is based on the Neural Network to predict the values and also generates rules similar to Decision Tree which is easy to interpret. Similarly researches are being carried out in many places to extract rules from Neural Networks and they are called with different names such as artificial neural-network decision tree algorithm (ANN-DT) [10], Neural Network Extraction Rules (NNER), Tree Based Neural Networks (TBNN) [11], Rule Generation from Neural Networks [12], Fuzzy Decision Trees [13] etc.
3.3 Conclusions and comments
Though Multilayer Perceptron consumes relatively more time for learning than J48, the outcome (accuracy) is appreciable and the interpretability of Decision tree is intresting. In general, both Decision Trees and Neural Networks has advantages and drawbacks, hence the current research is towards constructing a Hybrid algorithm which encompasses advantages of both the algorithms i.e., accuracy and performance of Neural Networks and the interpretability of Decision Trees.
4Appendix - Acronyms
| Term | Definition |
|---|---|
| CSV | Comma Separated Values |
| DTS | Data Transformation Services |
| ARFF | Attribute-Relation File Format |
| MLP | Multilayer perceptron |
| ANN-DT | Artificial Neural-Network Decision Tree Algorithm |
| NNER | Neural Networks Extraction Rules Algorithm |
| TBNN | Tree based Neural Networks |
5 Bibliography
[1] Archive, U. K. (1999). "KDD Cup 1999 Data." Retrieved April 20, 2009, from http://kdd.ics.uci.edu/databases/kddcup99/task.html
[2] Corporation, T. C. (1999). Introduction to Data Mining and Knowledge Discovery. Potomac, MD (U.S.A), Two Crows Corporation.
[3] Cscu.cornell.edu, 2003 [Online] Simona Despa, 4 March 2003 Retrieved from http://www.cscu.cornell.edu/news/statnews/stnews55.pdf [Accessed on May 5, 2009]
[4] Fu, L. (1994). "Rule generation from neural networks." IEEE Transactions on Systems, Man and Cybernetics 24(8): 1114-1124.
[5] Halgamuge, S. K. and L. Wang (2005). Classification and clustering for knowledge discovery. Berlin ; New York, Springer.
[6] Han, J. and M. Kamber (2006). Data mining : concepts and techniques. Amsterdam ; Boston San Francisco, CA, Elsevier ; Morgan Kaufmann.
[7] Irena IVANOVA, M. (1995). Initialization of Neural Networks by Means of Decision Tree. Knowledge Based Systems. Sofia, Bulgaria.
[8] Janikow, C. Z. (1998). "Fuzzy decision trees: issues and methods." IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 28(1): 1-14.
[9] José M. Jerez-Aragonésa, J. A. G.-R., Gonzalo Ramos-Jiméneza, José Muñoz-Péreza, Emilio Alba-Conejob (2003). "A combined neural network and decision trees model for prognosis of breast cancer relapse." Artificial Intelligence in Medicine 27(1): 45-63.
[10] Larose, D. T. (2005). Discovering knowledge in data : an introduction to data mining. Hoboken, N.J., Wiley-Interscience.
[11] Schmitz, G. P. J. A., C. Gouws, F.S. (1999). "ANN-DT: an algorithm for extraction of decision trees fromartificial neural networks." IEEE Transactions 10(6): 1392-1401.
[12] Stephen P. Curram, J. M. (1994). "Neural Networks, Decision Tree Induction and Discriminant Analysis: An Empirical Comparison." Operational Research Society 45(4): 440 - 450.
[13] Witten, I. H. and E. Frank (2005). Data mining : practical machine learning tools and techniques. Amsterdam ; Boston, MA, Morgan Kaufman.
[14] Yacine Bouzida (n.d.), "Neural networks vs. decision trees for intrusion detection" Source: Mitsubishi Electric ITE-TCL
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.